AI won't come for your job yet, and that's bad
Bottom line up front: I suspect that we will see an eyewatering spike in inference costs due to macro risks, evaporation of inference subsidies, and questionable productivity improvements from AI adoption with current models. If inference costs increase, they will make all but the least powerful models unaffordable for the average person and enterprise. This will limit the potential for rapid societal and economic transformation, relegating us to a reality where AI is another tool like email that usually works well but can't automate most things in its own right. I would like to see a different future. I think a world where jobs are automated en masse could be good for reorienting humans toward creativity and community, and some actionable things I believe we can do to increase the probability of that outcome are: create, research how to make inference cheaper, contribute to Scalable Formal Oversight, and build community.
I work in software, and since the beginning of this year, 2026, I have been investing in deeply integrating AI into my workflow. AI has gotten strikingly good at coding, to the point where it writes more than 90% of my code, and many of my coworkers at Stripe are reporting a similar experience. Everyone in software that I talk to agrees: Anthropic's Opus 4.6 unleashed a vibe shift in coding capability. A world where software engineering is mostly automated feels within reach.
Although there are many questions unanswered about the safety of mass AI adoption, I think there is great potential for the replacement of jobs by AI to create a remarkably improved stan1d of living, where humans can be free of most material constraints and return to a state of creativity and community-oriented living. The transitional period might be painful, but I am generally optimistic about what a fully AI-driven future could look like. We can maximize our chances of success if we pair a push for powerful AI-driven job automation with Scalable Formal Oversight (SFO).
If we don't act now, this generational opportunity might fade away. One way it could fade is if inference costs rise substantially. Recently, I caught wind of news that a large software company (name omitted for privacy) is pumping the brakes on AI spend. The team responsible for rolling out AI tools must have received a directive to start constraining costs because the company's bottom line was starting to feel it, and they forced all engineers to use a lower tier model unknowingly. In response, several engineers at the company grumbled about how the lower model tier's output was noticeably worse, and it led to wasted cycles spent on reviewing and correcting the worse model's output.
This got me thinking about whether the AI adoption and job replacement scenarios painted in pieces like the Citrini report and Matt Schumer's now infamous Something Big Is Happening post are realistic in our current world.
My take is that AI labor replacement is not going to happen yet. AI inference will get significantly more expensive due to macro and geopolitical risks and the fleeting nature of investor subsidies of inference. If that happens, the demand for inference that's fueling the AI buildout could evaporate due to prohibitively high costs, thus completing the boom-bust cycle. I'm disappointed about this because I believe that this technology has the potential to transform the way we work and live, but all hope is not lost; there are several strategic directions in which we can collectively push to maximize the likelihood of a good outcome.
By the end of this post, I hope to reinvigorate in you (and myself, quite frankly) a revolutionary spirit with some thoughts about what actions we can take to try to generate escape velocity from the boring future where AI becomes a half-decent tool that makes work more annoying and exhausting. But to start, here are the main pillars of my argument:
-
AI buildout is bottlenecked: Constraints on the manufacturing of critical inputs limit the AI buildout. Recent geopolitical instability and its effects on energy prices threaten to further dampen progress.
-
Inference costs are being held artificially low: Investor money is subsidizing the free tiers of frontier labs. We should expect inference costs to rise substantially if the frontier labs providing the models we know and love want to stay in business.
-
Humans are now the bottleneck more than ever: Investment in AI tools are reportedly not generating ROI for many enterprises. AI helps workers do more, but the limits of cognitive load of managing and communicating with AI agents in parallel are becoming apparent.
Expect inference costs to increase
When an environment changes, systems operating in that environment either fail or adapt. The release of ChatGPT in 2022 changed the environment, and three and a half years later, our economic system is still in the process of adapting.
How quickly different parts of the economy can adapt is variable. Software adapts very quickly, hardware, more slowly, and physical manufacturing infrastructure adapts at a snail's pace. It is therefore unsurprising that the chokepoints of the AI buildout are in the realm of the physical: power and silicon.
Frontier labs are also underpricing inference, drawing down their prodigious cash reserves to cover their costs. If the macro risk flares up, then capital might dry up before profitability is reached.
Risk 1: Macro
If you're tapped into the sphere of popular tech podcasts, such as the Cheeky Pint podcast by John Collison, cofounder of Stripe, you may have heard Elon Musk in a recent episode talking about a severe shortage of the turbines that are used to convert natural gas into electricity. Gas-fired turbine lead times have soared to as much as seven years. That means that if you aren't already in the queue, you're waiting close to a decade to getting just the turbines, which are necessary but not sufficient to generate electricity from natural gas.
The supply of natural gas itself, along with oil, are also being threatened. Recent US military action in Iran has effectively closed the strait of Hormuz, which is disrupting global oil and liquefied natural gas (LNG) supply. According to Reuters, the situation in the strait has removed around 400 million barrels from the market, "triggering price increases of around 50%." This crisis may be transient, and we will see how things play out in the coming weeks, but it highlights the US and world economies' sensitivity to global conflict.
These circumstances may restrict how quickly new data centers can come online, depending on what fuel source they choose. Gartner estimates 2025 data center power consumption 448 TWh, and they estimate it to grow to 980 TWh in 2030. In their model, power consumption by data centers more than doubles in five years, while growth in power generation across the board in the US is alarmingly stagnant.1
As for silicon, TSMC, a Taiwanese corporation, represents a single point of failure for the US tech industry. In Q2 2025, TSMC captured a record 70.2% of chip foundry market share. According to Nasdaq, TSMC has an even higher share, 90%, of advanced chip manufacturing, which includes 3-nanometer chips that are becoming standard. TSMC poses obvious geopolitical risk as well, as is a mere 100 miles off the coast of China. One well targeted and well timed attack could disrupt AI adoption by limiting how much compute can get built out in the short term. There is no telling how long it would take to reach original production capacity again if there were significant damage to the dense network of fabs, raw materials suppliers, and research institutions on Taiwan's west coast.
Ostensibly in response to these risks, the US government pressured TSMC to spin up a fab in Arizona. The fab has been built, but TSMC Arizona already lags behind Taiwan in the set of manufacturing processes that are available. TSMC is currently capable of lithography down to 2 nanometer scale, and cloud service providers are rushing to adopt it, but 2nm and the older 3nm processes are slated to be made available in the Arizona plant in 2029 and 2027, respectively. In Taiwan, a 1nm fab is already set for Tainan. US-based fabs have a lot of catch-up to do. We must have parity with the state of the art in chip manufacturing before the supply chain and geographical dependencies can be eliminated.
These are far from the only risks to chip fabrication either. Just as I was drafting this post, a notification lit up my phone: "An Invisible Bottleneck: A Helium Shortage Threatens the Chip Industry".
It becomes hard to justify underpricing inference when the cost of the physical utility infrastructure might blow up, and it's impossible to justify underpricing when there is no capital to subsidize inference. This brings us to the next risk: capital.
Risk 2: Capital well runs dry
Let's look at some numbers, using OpenAI as an example. Several different sources cite different revenue and cost figures for OpenAI, and it is a private company, so it is difficult to know their true financials with certainty. At a minimum, however, we can certainly say OpenAI is losing money at an astounding clip. Epoch AI estimates that OpenAI was significantly unprofitable in 2024, making $3.7 billion revenue on $1.8 billion inference spend and roughly $6 billion total compute spend, including inference. This implies a plausible 50% gross margin on inference, but a negative net margin that investors are covering.
In 2025, OpenAI reported $4.3 billion in 2025H1 and projected $13 billion for full year. "Against that revenue, they’re spending approximately $22 billion," representing a shortfall of $9 billion that investors are subsidizing. This shortfall is set to increase, as further research from Epoch AI shows that on a large scale, training compute costs have been doubling every 8 months, or 2.7x per year.
OpenAI and their investors are well aware of the capital requirements to keep the lights on with inference as well as in the R&D department. The company is fresh off a record fundraise of $120 billion. Even with that much capital, OpenAI still has to be judicious. Just last week, OpenAI decided to shut down Sora, the video generation app released several months ago. OpenAI's CFO, Sarah Friar, said on CNBC, "We are just facing a lack of compute." TechCrunch cites the Wall Street Journal's analysis of the situation, stating that "Claude Code, in particular, was eating OpenAI’s lunch."
If the macro risks increase, leading to costlier compute, OpenAI may not be able to make the rounds with investors to raise eyewatering amounts of money much longer. Furthermore, all this is moot if these models don't perform in real-world deployments. With 61% of senior business leaders feeling increased pressure to prove ROI compared to a year ago, and 71% of global CIOs saying their AI budgets would be cut if value from AI couldn't be demonstrated within 2 years, fiscal reality may start settling in soon. If poor performance metrics coincide with a compute cost spike, AI investment and adoption fervor could rapidly deteriorate.
The competition is fierce. I predict that being able to manage costs will soon become a moat. A good example of this is Cursor. They leveraged their unique dataset of software engineer conversations with AI to build in-house models that are domain-specific for coding and far less expensive to run. If capital runs out, labs like OpenAI and Anthropic will have to either cut costs or significantly increase the cost of using their products, restricting the accessibility of powerful AI. If only mediocre AI remains accessible, we will settle into a stationary point of productive capacity where humans remain the bottleneck.
Humans are more of a bottleneck than ever
Working with AI tools has a strange allure, almost an addictive quality. The gap between dream and reality has shortened, so the dopamine hit we get from completing a task is closer and more predictably reachable.
This thrill has enabled us to take on more work. I can attest that there is a thrill to being able to kick off a new agent session when an idea comes to my head instead of having to invest the mental effort of thinking through what I'm trying to do. This is a pattern that is appearing across the economy. According to research published in HBR,
On their own initiative workers did more because AI made "doing more" feel possible, accessible, and in many cases intrinsically rewarding.
The researchers warn, however, that this early period of experimentation could morph into cognitive overload, reducing quality of work output and decision-making in the long term.
Humans have a fundamentally serial input-output interface. We fail at multitasking, and there is a well-established body of research that corroborates this.2 AI, on the other hand, can be virtually infinitely parallelized, producing more output per unit time than is humanly possible to review and understand in a timely fashion, and trying to switch between parallel threads deleteriously imposes cognitive overhead. This effect, sometimes referred to as "AI Brain Fry" is analogous to thrashing on computers. It is a slowdown caused by the serialization of infinite parallel AI workstreams, and the temptation to add more workstreams to "be more productive."
This all points to the need to develop a better working relationship with AI. Perhaps we need to be able to entrust it with longer horizon tasks so that we aren't as crushed by the mathematics of how much effort it takes for our brains to switch context and enter deep focus mode. I'll take this one step further: task time horizon where AI can reliably (>>90%) execute tasks independently is the most important dimension for job replacement. It is more important than cost because capital can be acquired if the return-on-investment potential is there (i.e. loans).
Reliable long horizon task completion, however, still eludes even the most powerful models. According to the METR task completion time horizon evaluation, Opus 4.6 can complete a task that would take a human 1 hour and 10 minutes with only 80% reliability.3 80% reliability is significantly less reliable than a well-calibrated human in a workplace. Correcting the output of AI 20% of the time for long horizon tasks and having to context switch frequently to manage many short horizon tasks doesn't sound like a healthy, productive working model to me.
So for the time being, it seems that we are stuck in this rut where AI works decently well but leaves us cognitively exhausted due to managing it. If future AI can achieve reliability figures in the high 90s but only with extremely high cost, such that ROI still remains questionable, then the fantasies of Citrini-style job replacement vanish.
How can we manifest the "good ending?"
Now, as promised, I would like to paint a different picture and suggest strategic directions in which we can collectively push to manifest what I'm calling the "good ending," where job replacement does happen and it enables us to become our true creative, soulful, human selves.
Upon reading the above, you might be wondering, "why is the current state suboptimal?" and "how does job replacement enable this vision of yours?" These are fair questions, and it is true that these are not guarantees. Work gives many people a sense of purpose, and many people may not want to lose that. However, community involvement can also grant a sense of purpose. I have felt this in my own life. Spending time with my family and community and helping them out motivates me like few other things in the world. I think one of the tragedies of our modern economic system is that community-building has fallen by the wayside.
Alongside community is creativity which seems uniquely able to form within us a moral conscience. For exaxmple, Uncle Tom’s Cabin by Harriet Beecher Stowe sent waves through the northern states, greatly furthering the abolitionist cause. Literature, art, and other creative works transmit memories of human pain and suffering of the past, helping us learn and reflect in the process. I believe humanity benefits from being able to spend lots of time creating and reflecting on creative works.
AI displacement of jobs enables community-orientation and creativity simply by returning to us the choice of what we do with our time. Many of us may choose to keep working, and that's fine. Many jobs have space for the creative work I described.4 Many of us may choose other pursuits. It is not a given that our governmental systems will respond in kind by allocating resources appropriately in a post-work world, but I remain optimistic that we can prosper nonetheless.5 Without needing to sacrifice community to make a living, we can turn towards our neighbors and connect with them. We can generate new cultures and traditions.
This line of thinking calls to mind the Greek culture that I grew up in. There are rich regional traditions of music, dance, cuisine, customary celebrations, and other cultural artifacts generated from generations of playful experimentation.
These thoughts have parallels with and draw inspiration from this post by Jordan Hall on X. Shoutout to my friend Nick Makiej for finding it and sharing it with me. Now, the following are the directions I suggest we push toward to generate this reality.
1. Create
New generations of AI models are currently getting trained on immense amounts of AI slop content that was generated by past generations of models. Epoch AI predicts we will soon run out of human-generated data to train on. Andrej Karpathy expressed concern about this as well in his discussion of the notion of "entropy" in his interview with Dwarkesh Patel. Entropy is a formal term in information theory, but Andrej was using it in more of informal sense in the interview, to denote the quality of "newness" of information. Trainers of models have been exploring using LLMs to generate synthetic data to train on. Karpathy is skeptical of this approach, however.
Here is an excerpt from the interview:
The LLMs, when they come off, they’re what we call “collapsed.” They have a collapsed data distribution. One easy way to see it is to go to ChatGPT and ask it, “Tell me a joke.” It only has like three jokes. It’s not giving you the whole breadth of possible jokes. It knows like three jokes. They’re silently collapsed.
You’re not getting the richness and the diversity and the entropy from these models as you would get from humans. Humans are a lot noisier, but at least they’re not biased, in a statistical sense. They’re not silently collapsed. They maintain a huge amount of entropy. So how do you get synthetic data generation to work despite the collapse and while maintaining the entropy? That’s a research problem.
I tried this myself to see if Karpathy was right, using the free version of ChatGPT on March 22nd, 2026 (this isn't a very reproducible experiment, because OpenAI hides which model is being used on the free version). On the fourth try, ChatGPT repeated the same joke as the third try:
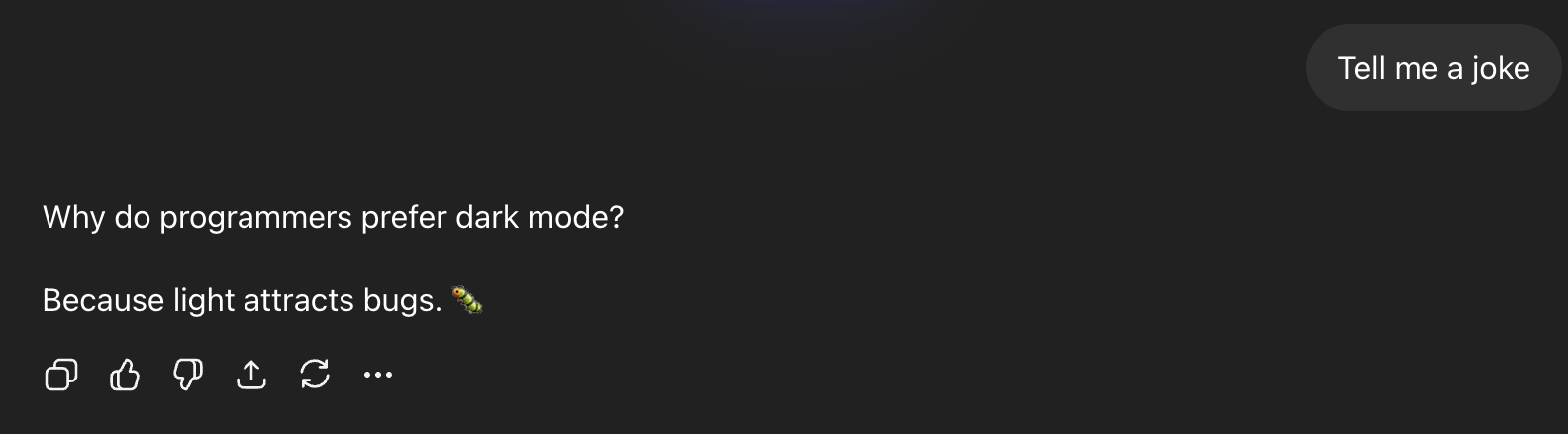
The upshot here is that we as humans still have a lot to offer. Maybe inference doesn't have to decrease substantially in cost if we can collectively provide current models with more entropy per token.
Each of us contains a deep well of entropy, informed by our unique personal experiences and story. This is what inspired me to start this blog. I used AI to research this piece, but I wrote every word on this page by hand because I wanted this blog to reflect my entropic voice.
Go forth, create, and create with high quality.
2. Participate in research to make AI more cost effective to train and run
The further we drive down the cost of inference, the more likely it is that we'll be able to generate escape velocity and drive meaningful adoption of AI in workplaces and among people at the edge.
Research in quantization, distillation, and pruning has made strides toward making LLM inference runnable on cheap hardware such as phones, but with a slight accuracy penalty. Figuring out how to mitigate that tradeoff is an interesting research direction.
I think alternatives to the LLM architecture are also underexplored. Drawing from the Mamba architecture, for instance, could lead to significant efficiency improvements, as Mamba's attention has linear time complexity whereas standard transformer model attention layers have quadratic time complexity.
My good friend Dana recently joined Subconscious, a startup leveraging research out of MIT which proposes a codesigned thread inference architecture and runtime for long horizon tasks. Codesign, though harder to implement and not generalizable, can have tremendous efficiency benefits because each part of the system is aware of how it needs to interact with the others to maximize efficiency and accuracy. Architecture-runtime codesign is a great first step. I would love to see this taken a step further toward runtime-chip codesign as well. MatX is a startup building chips for inference, and I expect they've done some thinking about this.
A nice consequence of all this is that cheap inference that can be run with consumer hardware at the edge also solves the energy bottleneck. The power grid is designed to handle marginal load increases at its edges, but not well equipped to handle a massive spike in load at a single geographical point. This might even resolve some of the silicon bottleneck too; consider how much compute there is around us lying dormant on devices like smartphones, tablets, even our laptops.
There is lots of interesting work to be done here, and I look forward to seeing it.
3. Participate in the Scalable Formal Oversight initiative
The obvious risk posed when racing towards the "good ending" is the AI doomer's fantasy: what if AI takes over and starts misbehaving?
This is not a fantasy. The AI of today misbehaves often. Large language models are known to engage in deceptive behavior to make human evaluators think that they are more aligned with human intentions than they actually are. Code that agents output can be unsafe and destructive. A verification harness for the actions that AI agents take is crucial. In my view, it is a prerequisite for any significant job replacement in safety critical domains, and it is likely necessary in order to actually enable large scale replacement in software engineering, for instance, where high level goals can be very long horizon, and contexts can grow very large. Agents are likely prone to mistakes that may be avoidable with verification guardrails.
Read Max von Hippel's post Scalable Formal Oversight, and take it seriously!
4. Build community
At the end of the day, community is all we have. If AI frees us from most material constraints, then we can return to a world of playful creativity, cheer, and communal bonds. This is a world I'd love to live in.
If this resonates with you, get in touch!
Why I could be wrong
To recapitulate: my core thesis is that we can expect AI inference to get significantly more expensive, due to macro risks and venture capital inference subsidies running out. Cheap access to AI inference at the frontier of capability is necessary to support nontrivial levels of job replacement, so we will likely land in a situation where fervor around AI will slow greatly.
Here are some rapid-fire reasons why I could be wrong:
- Perhaps progress in making inference cheaper at the hardware level will speed up. MatX is a chip startup hoping to reinvent how AI inference is done at a hardware level, which is compelling, and perhaps they will have some breakthrough.
- Perhaps the geopolitical risks of today will evaporate tomorrow.
- Perhaps the buildout will proceed more smoothly than I think it will, with TSMC's Arizona buildout proceeding as planned or better than planned.
- Perhaps the problem isn't inference cost, but context management or other algorithmic inefficiencies (another shoutout to Dana at Subconscious), and better context management is an active research area. We could generate escape velocity if we can solve these challenges and unlock more consistent ROI.
- Perhaps most industries won't actually require highly capable LLMs to be mostly automated.
- Perhaps people are still learning how to most effectively use AI. A recent report from Anthropic suggests this very effect. Longer tenure users of Claude are 4% more likely to have successful conversations, even after controlling for model type, use case, and country/language. Multitasking is also a skill that appears to be trainable.
There are probably more reasons. Send me an email if you have a comment! This post is an essay6 in the true sense of the word.
Each of these probably deserves more exploration, but I did not have the time or space to get them into this piece. I may return to some of these pushbacks in future posts, so stay tuned!
Final word
Thank you for making it this far. This is the first blog post that I'm officially publishing, so I would appreciate any and all feedback. Please drop me an email at s.xifaras999@gmail.com if you would like to leave feedback, positive or critical, or just want to chat. If you're in the northeastern US (NYC-Boston range), let me know and I'd love to explore an in-person meeting!
Victor and Nick, thank you for your helpful feedback on drafts of this post.
- Look at the "Total Generation at Utility Scale Facilities" column in the Annual Totals group. In 2014, power generation was 4,093,564 GWh, and in 2025, it was 4,308,634 GWh. This is a mere 5.2% increase in 11 years! ↩
- See Section 2, "Cognitive Workload in Multitasking Environments," in the cited systematic literature review. ↩
- And the true task time horizon value might be even less. I don't think METR's benchmark generalizes well. I may write a follow-up post about this. ↩
- Software engineering, for instance. That's why I enjoy it. ↩
- I plan on returning to more practical thoughts on how governments can respond to such societal change in a future post. ↩
- French for "attempt" ↩